The PastaStore YAML interface
This notebook shows how Pastas models can be built from YAML files, using Pastastore.
Contents
import os
from io import StringIO
import pastas as ps
import yaml
import pastastore as pst
# Set pastas log messages to ERROR level
ps.set_log_level("ERROR")
Why YAML?
YAML, according to the official webpage is “YAML is a human-friendly data serialization language for all programming languages”. The file structure is similar to JSON (nested dictionaries) and therefore similar to the storage format for pastas Models, i.e. .pas-files.
So why develop a method for reading/writing pastas models to and from YAML files? The human-readability of the file structure in combination with leveraging tools in pastastore allow users to quickly build pastas Models using a mini-language, without having to explicitly program each line of code. When users are working with a lot of models with different model structures, the YAML files can provide a simple and convenient interface to structure this work, without having to search through lots of lines of code.
Whether it is useful to “program” the models in YAML or in normal Python/pastas code depends on the application or project. This feature was developed to give users an extra option that combines human-readable files with useful tools from the pastastore to quickly develop pastas models.
An example YAML file
A YAML file is text file that uses Python-style indentation to indicate nesting. The following shows the structure of a YAML file for defining a pastas model.
# comments are allowed, this is a pastas Model:
my_first_model: # model name
oseries: head_nb1 # head time series name, obtained from pastastore
stressmodels: # stressmodels dictionary
recharge: # name of the recharge stressmodel
class: RechargeModel # type of pastas StressModel
prec: prec1 # name of precipitation stress, obtained from pastastore
evap: evap1 # name of evaporation stress, obtained from pastastore
recharge: Linear # pastas recharge type
rfunc: Exponential # rfunc
Reading this file converts it into a nested dictionary, as shown below. This dictionary can be used to (re-)construct pastas models, as is shown in the next sections.
yaml_file = """
# comments are allowed, this is a pastas Model:
my_first_model: # model name
oseries: head_nb1 # head time series name, obtained from pastastore
stressmodels: # stressmodels dictionary
recharge: # name of the recharge stressmodel
class: RechargeModel # type of pastas StressModel
prec: prec1 # name of precipitation stress, from pastastore
evap: evap1 # name of evaporation stress, from pastastore
recharge: Linear # pastas recharge type
rfunc: Exponential # response function
"""
# load the file
d = yaml.load(StringIO(yaml_file), Loader=yaml.Loader)
# view the resulting dictionary
d
{'my_first_model': {'oseries': 'head_nb1',
'stressmodels': {'recharge': {'class': 'RechargeModel',
'prec': 'prec1',
'evap': 'evap1',
'recharge': 'Linear',
'rfunc': 'Exponential'}}}}
The PastaStore.yaml interface
The logic for reading/writing YAML files is accessed through the PastaStore.yaml interface. First we need a PastaStore and fill it with some data to showcase this. Load the example dataset from the PastaStore (included since version 0.8.0 (note, this data is only available if the pastastore repository was cloned and not if it was installed with pip).
from pastastore.datasets import example_pastastore # noqa: E402
pstore = example_pastastore()
pstore
<PastaStore> example:
- <DictConnector> 'my_db': 5 oseries, 15 stresses, 0 models
Let’s check which oseries are available:
pstore.oseries
| x | y | |
|---|---|---|
| name | ||
| oseries1 | 165000.0 | 424000.0 |
| oseries2 | 164000.0 | 423000.0 |
| oseries3 | 165554.0 | 422685.0 |
| head_nb5 | 200000.0 | 450000.0 |
| head_mw | 85850.0 | 383362.0 |
Building model(s) from a YAML file
Note that pstore.yaml.load() can take both a path to a YAML file as its first
argument, as well as a YAML-formatted string like the one defined below.
my_first_yaml = """
my_first_model: # model name
oseries: oseries1 # head time series name, obtained from pastastore
stressmodels: # stressmodels dictionary
recharge: # name of the recharge stressmodel
class: RechargeModel # type of pastas StressModel
prec: prec1 # name of precipitation stress, from pastastore
evap: evap1 # name of evaporation stress, from pastastore
recharge: Linear # pastas recharge type
rfunc: Exponential # response function
"""
ml = pstore.yaml.load(my_first_yaml)[0] # returns a list, so get the first entry
ml
Building model 'my_first_model' for oseries 'oseries1'
| parsing stressmodel: 'recharge'
Model(oseries=oseries1, name=my_first_model, constant=True, noisemodel=False)
ml.solve(report=False)
_ = ml.plots.results()
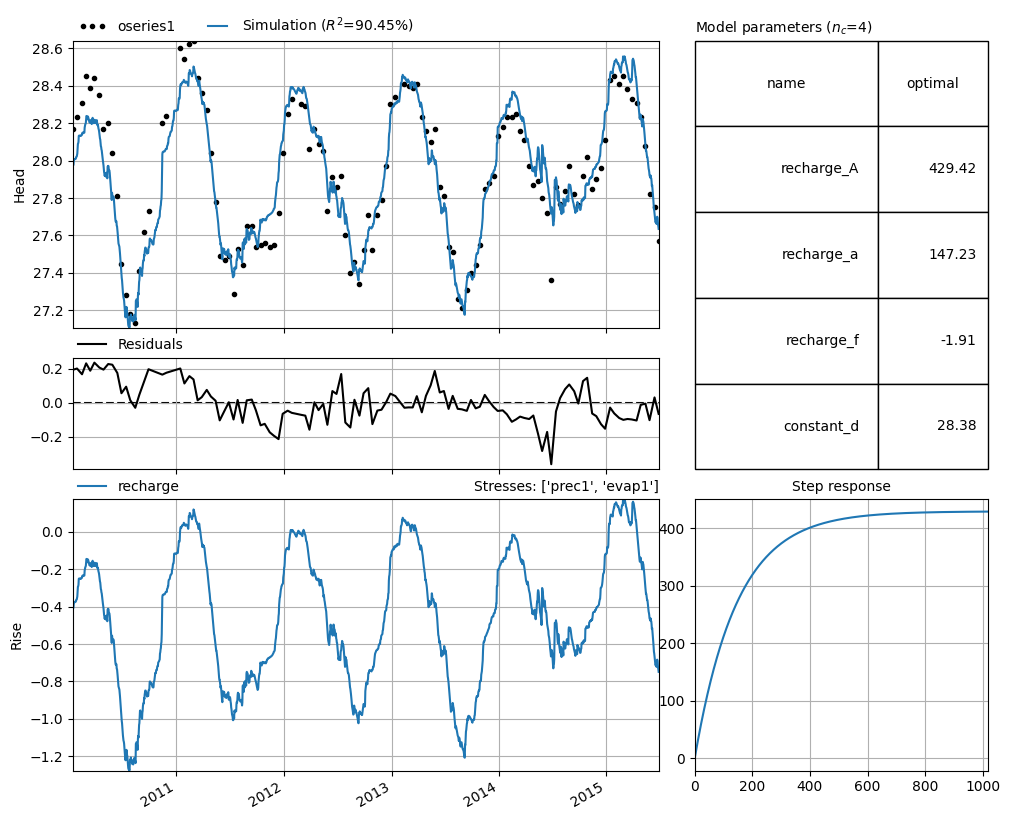
A YAML file can contain multiple models
my_multi_model_yaml = """
my_first_model: # model name
oseries: oseries1 # head time series name, obtained from pastastore
stressmodels: # stressmodels dictionary
recharge: # name of the recharge stressmodel
class: RechargeModel # type of pastas StressModel
prec: prec1 # name of precipitation stress, from pastastore
evap: evap1 # name of evaporation stress, from pastastore
recharge: Linear # pastas recharge type
rfunc: Exponential # response function
my_second_model: # model name
oseries: oseries1 # head time series name, obtained from pastastore
stressmodels: # stressmodels dictionary
recharge: # name of the recharge stressmodel
class: RechargeModel # type of pastas StressModel
prec: prec1 # name of precipitation stress, from pastastore
evap: evap1 # name of evaporation stress, from pastastore
recharge: FlexModel # pastas recharge type
rfunc: Exponential # response function
"""
models = pstore.yaml.load(my_multi_model_yaml)
models
Building model 'my_first_model' for oseries 'oseries1'
| parsing stressmodel: 'recharge'
Building model 'my_second_model' for oseries 'oseries1'
| parsing stressmodel: 'recharge'
[Model(oseries=oseries1, name=my_first_model, constant=True, noisemodel=False),
Model(oseries=oseries1, name=my_second_model, constant=True, noisemodel=False)]
Note that these models are not automatically added to the PastaStore. They are only created. To store them use PastaStore.add_model.
for ml in models:
pstore.add_model(ml)
pstore
<PastaStore> example:
- <DictConnector> 'my_db': 5 oseries, 15 stresses, 2 models
Writing model(s) to a YAML file
Writing an existing model to a YAML file is done with PastaStore.yaml.export_model(). The resulting YAML file contains a lot more information as all model information is stored in the file, similar to saving a model as .pas-file with ml.to_file(). It can be useful to take a look at this file as a template for writing your own YAML files.
pstore.yaml.export_model(ml)
The YAML file can be simplified with the minimal_yaml keyword argument.
ml.name = ml.name + "_minimal"
pstore.yaml.export_model(ml, minimal_yaml=True)
Additionally, the use_nearest option fills in "nearest <n> <kind>" instead of the names of the time series, filling in <n> and <kind> where possible. This option is only used when minimal_yaml=True.
ml.name = ml.name + "_nearest"
pstore.yaml.export_model(ml, minimal_yaml=True, use_nearest=True)
The models can als be written to a single YAML-file using PastaStore.yaml.export_models(). The split=False kwarg forces all models to be written to the same file.
pstore.yaml.export_models(models=models, split=False)
“Nearest” options for time series
The YAML file format introduces some useful features that leverage useful tools in PastaStore. Instead of explicitly defining the time series to use for a particular stressmodel, there is a nearest option. Note that this requires the metadata of the time series in the PastaStore to be properly defined, with x and y coordinates for all time series.
First let’s revisit the first example YAML file, but this time use the “nearest” option to select the precipitation and evaporation time series. After nearest the kind identifier is supplied to tell the PastaStore which types of stresses to consider when looking for the nearest one.
nearest_yaml = """
my_first_model: # model name
oseries: oseries1 # head time series name, obtained from pastastore
stressmodels: # stressmodels dictionary
recharge: # name of the recharge stressmodel
class: RechargeModel # type of pastas StressModel
prec: nearest prec # nearest stress with kind="prec", from pastastore
evap: nearest evap # nearest stress with kind="evap", from pastastore
recharge: Linear # pastas recharge type
rfunc: Exponential # response function
"""
ml = pstore.yaml.load(nearest_yaml)[0] # returns a list, so get the first entry
ml
Building model 'my_first_model' for oseries 'oseries1'
| parsing stressmodel: 'recharge'
| using nearest stress with kind='prec': 'prec1'
| using nearest stress with kind='evap': 'evap1'
Model(oseries=oseries1, name=my_first_model, constant=True, noisemodel=False)
The nearest option is parsed depending on the type of stressmodel. Generally, the form is nearest <kind>, but for the RechargeModel, just providing nearest will assume the kind is kind="prec" or kind="evap".
For WellModel, the number of nearest stresses can be passed as well, e.g. nearest <n> <kind>.
The following examples illustrate this:
full_nearest_yaml = """
nearest_model_1: # model name
oseries: head_nb5 # head time series name, obtained from pastastore
stressmodels: # stressmodels dictionary
recharge: # name of the recharge stressmodel
class: RechargeModel # type of pastas stressmodel
prec: nearest # nearest stress with kind="prec", from pastastore
evap: nearest evap # nearest stress with kind="evap", from pastastore
recharge: Linear # pastas recharge type
rfunc: Exponential # response function
river: # name for river stressmodel
class: StressModel # type of pastas stressmodel
stress: nearest riv # nearest stress with kind="riv", from pastastore
rfunc: One # response function
settings: level # time series settings
nearest_model_2:
oseries: head_mw
stressmodels:
recharge:
class: RechargeModel
prec: nearest prec
evap: nearest
recharge: Linear
rfunc: Exponential
wells:
class: WellModel
stress: nearest 2 well
rfunc: HantushWellModel
up: False
"""
pstore.oseries
| x | y | |
|---|---|---|
| name | ||
| oseries1 | 165000.0 | 424000.0 |
| oseries2 | 164000.0 | 423000.0 |
| oseries3 | 165554.0 | 422685.0 |
| head_nb5 | 200000.0 | 450000.0 |
| head_mw | 85850.0 | 383362.0 |
models = pstore.yaml.load(full_nearest_yaml)
Building model 'nearest_model_1' for oseries 'head_nb5'
| parsing stressmodel: 'recharge'
| using nearest stress with kind='prec': 'prec_nb5'
| using nearest stress with kind='evap': 'evap_nb5'
| parsing stressmodel: 'river'
| using nearest stress with kind='riv': riv_nb5
Building model 'nearest_model_2' for oseries 'head_mw'
| parsing stressmodel: 'recharge'
| using nearest stress with kind='prec': 'prec_mw'
| using nearest stress with kind='evap': 'evap_mw'
| parsing stressmodel: 'wells'
| using 2 nearest stress(es) with kind='well': ['extraction_2' 'extraction_3']
ml = models[0] # get the first model from the list
ml.solve(report=False)
ml.plots.results()
[<Axes: xlabel='Date', ylabel='Head'>,
<Axes: >,
<Axes: title={'right': "Stresses: ['prec_nb5', 'evap_nb5']"}, ylabel='Rise'>,
<Axes: title={'center': 'Step response'}>,
<Axes: title={'right': "Stresses: ['riv_nb5']"}, ylabel='Rise'>,
<Axes: title={'center': 'Step response'}>,
<Axes: title={'left': 'Model parameters ($n_c$=5)'}>]
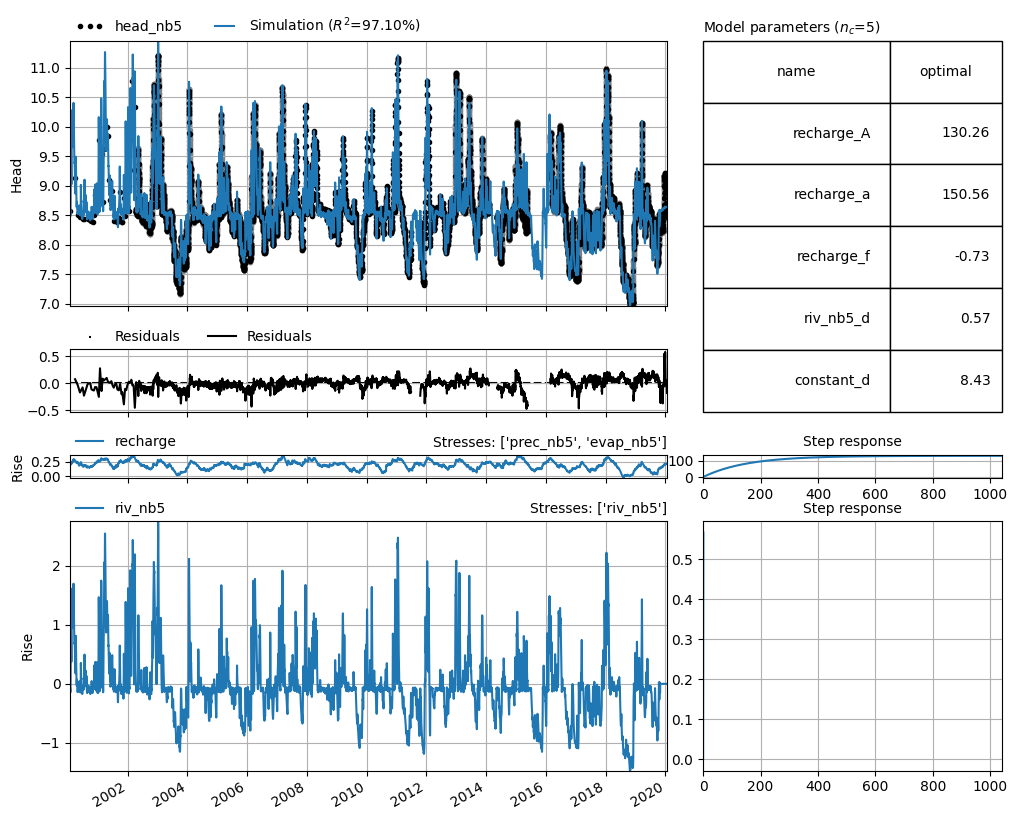
Defaults
The Pastastore YAML interface adds some additional defaults. These defaults allow the user to only provide only certain information in a YAML file in order to construct a model. These defaults are determined based on commonly used options. It should be noted that these defaults are not necessarily appropriate in all situations, and it is highly recommended to try different models with different options. These defaults are therefore implemented to facilitate building models, but should not be deemed holy.
The YAML interface mostly uses the Pastas defaults, but adds some additional logic for stressmodels. When default settings implemented in the YAML interface are implemented, this is logged to the console.
RechargeModel:
If stressmodel name is one of “rch”, “rech”, “recharge”, or “rechargemodel”, assume stressmodel type is RechargeModel.
If no “prec” or “evap” keys are provided for RechargeModel, use the “nearest” option.
Default rfunc for RechargeModel is “Exponential”.
prec: accepts
nearestornearest <kind>, if onlynearestis provided, stresses in PastaStore must be labelled with kind=”prec”evap: accepts
nearestornearest <kind>, if onlynearestis provided, stresses in PastaStore must be labelled with kind=”evap”
StressModel:
If no “stressmodel” key is contained in dictionary, assume stressmodel type is StressModel
Default rfunc for StressModel is “Gamma”.
stress: accepts
nearestornearest <kind>, if only “nearest” is provided, uses whichever stress is nearest.
WellModel:
Default rfunc for WellModel is “HantushWellModel”.
If “up” is not provided, assume up=False, i.e. positive discharge time series indicates pumping.
stress: accepts
nearest,nearest <n>andnearest <n> <kind>, where n is the number of wells to add. If kind is not passed, stresses must be labelled with kind=”well” in PastaStore. If n is not passed, assumes n=1.
This is the shortest possible YAML file for a model with recharge, that makes use of all of the defaults for RechargeModel:
minimal_yaml = """
ml_minimal:
oseries: oseries2
stressmodels:
recharge:
"""
Note that the YAML load method recognizes the stressmodel name “recharge” and assumes the type of stress model should be RechargeModel. Additionally note the defaults as no other information is provided.
prec –> nearest stress with kind=”prec”
evap –> nearest stress with kind=”evap”
recharge –> Linear
rfunc –> Exponential
ml = pstore.yaml.load(minimal_yaml)[0] # returns a list, so get the first entry
Building model 'ml_minimal' for oseries 'oseries2'
| parsing stressmodel: 'recharge'
| no StressModel type provided, using 'RechargeModel' based on stressmodel name.
| using nearest stress with kind='prec': 'prec2'
| using nearest stress with kind='evap': 'evap2'
| no 'rfunc' provided, using 'Exponential'
| no 'recharge' type provided, using 'Linear'
ml.solve(report=False)
_ = ml.plots.results()
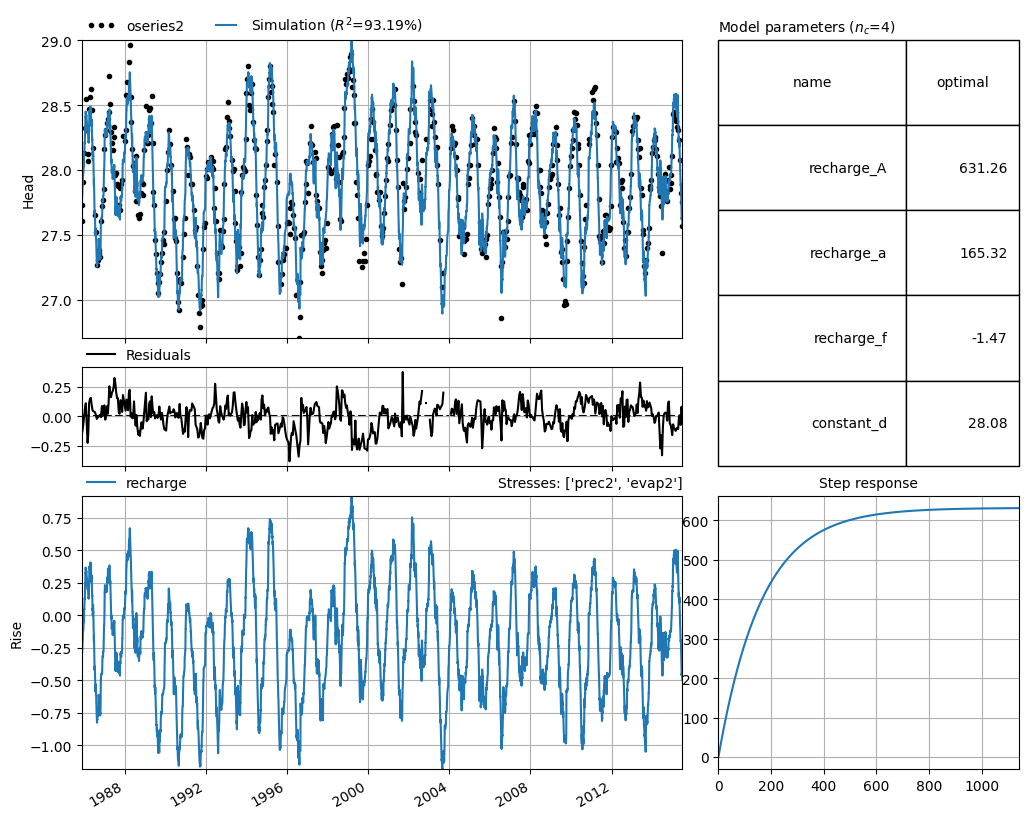
More examples
yaml_examples = """
# Pastas YAML example file
# ------------------------
# 1. Explicitly provide oseries, stresses names rfunc and
# recharge type.
ml_explicit:
settings:
freq: D
oseries: oseries1
stressmodels:
recharge:
class: RechargeModel
prec: prec1
evap: evap1
rfunc: Exponential
recharge: Linear
# 2. Provide oseries, stresses names but use defaults for
# other settings:
ml_stresses:
oseries: oseries1
stressmodels:
recharge:
prec: prec1
evap: evap1
# 3. Use "nearest" to obtain nearest precipitation and evaporation
# time series. Requires x, y data to be present in oseries and
# stresses metadata.
ml_nearest:
oseries: oseries1
stressmodels:
recharge:
prec: nearest prec
evap: nearest
"""
models = pstore.yaml.load(yaml_examples) # returns a list
models
Building model 'ml_explicit' for oseries 'oseries1'
| parsing stressmodel: 'recharge'
Building model 'ml_stresses' for oseries 'oseries1'
| parsing stressmodel: 'recharge'
| no StressModel type provided, using 'RechargeModel' based on stressmodel name.
| no 'rfunc' provided, using 'Exponential'
| no 'recharge' type provided, using 'Linear'
Building model 'ml_nearest' for oseries 'oseries1'
| parsing stressmodel: 'recharge'
| no StressModel type provided, using 'RechargeModel' based on stressmodel name.
| using nearest stress with kind='prec': 'prec1'
| using nearest stress with kind='evap': 'evap1'
| no 'rfunc' provided, using 'Exponential'
| no 'recharge' type provided, using 'Linear'
[Model(oseries=oseries1, name=ml_explicit, constant=True, noisemodel=False),
Model(oseries=oseries1, name=ml_stresses, constant=True, noisemodel=False),
Model(oseries=oseries1, name=ml_nearest, constant=True, noisemodel=False)]
The first and last models are identical, as shown in the comparison below (except for the name obviously). The second one is also the same, but is not shown in the comparison below.
pst.util.compare_models(
models[0], models[-1], detailed_comparison=True, style_output=True
)
| model 0 | model 1 | comparison | |
|---|---|---|---|
| name: | ml_explicit | ml_nearest | False |
| - settings: tmin | None | None | True |
| - settings: tmax | None | None | True |
| - settings: freq | D | D | True |
| - settings: warmup | 3650 days 00:00:00 | 3650 days 00:00:00 | True |
| - settings: time_offset | 0 days 00:00:00 | 0 days 00:00:00 | True |
| - settings: noise | False | False | True |
| - settings: solver | None | None | True |
| - settings: fit_constant | True | True | True |
| - settings: freq_obs | None | None | True |
| oseries: series_original | True | True | True |
| oseries: series | True | True | True |
| stressmodel: 'recharge' | recharge | recharge | True |
| - rfunc | Exponential | Exponential | True |
| - time series: 'prec1' | prec1 | prec1 | True |
| - prec1 settings: freq | D | D | True |
| - prec1 settings: sample_up | bfill | bfill | True |
| - prec1 settings: sample_down | mean | mean | True |
| - prec1 settings: fill_nan | 0.000000 | 0.000000 | True |
| - prec1 settings: fill_before | mean | mean | True |
| - prec1 settings: fill_after | mean | mean | True |
| - prec1 settings: tmin | 2010-01-01 00:00:00 | 2010-01-01 00:00:00 | True |
| - prec1 settings: tmax | 2015-12-31 00:00:00 | 2015-12-31 00:00:00 | True |
| - prec1 settings: time_offset | 0 days 00:00:00 | 0 days 00:00:00 | True |
| - prec1: series_original | True | True | True |
| - prec1: series | True | True | True |
| - time series: 'evap1' | evap1 | evap1 | True |
| - evap1 settings: freq | D | D | True |
| - evap1 settings: sample_up | bfill | bfill | True |
| - evap1 settings: sample_down | mean | mean | True |
| - evap1 settings: fill_nan | interpolate | interpolate | True |
| - evap1 settings: fill_before | mean | mean | True |
| - evap1 settings: fill_after | mean | mean | True |
| - evap1 settings: tmin | 2010-01-01 00:00:00 | 2010-01-01 00:00:00 | True |
| - evap1 settings: tmax | 2015-12-31 00:00:00 | 2015-12-31 00:00:00 | True |
| - evap1 settings: time_offset | 0 days 00:00:00 | 0 days 00:00:00 | True |
| - evap1: series_original | True | True | True |
| - evap1: series | True | True | True |
| param: recharge_A (init) | 211.567577 | 211.567577 | True |
| param: recharge_A (opt) | nan | nan | True |
| param: recharge_a (init) | 10.000000 | 10.000000 | True |
| param: recharge_a (opt) | nan | nan | True |
| param: recharge_f (init) | -1.000000 | -1.000000 | True |
| param: recharge_f (opt) | nan | nan | True |
| param: constant_d (init) | 27.927937 | 27.927937 | True |
| param: constant_d (opt) | nan | nan | True |
Clean up the written YAML files.
for f in [fi for fi in os.listdir(".") if fi.endswith(".yaml")]:
os.remove(f)